La différence entre un environnement de staging et un environnement live réside principalement dans leur usage et leur fonction dans le cycle de développement d’une application ou d’un site web.
- Environnement de Staging (Pré-production) :
- But : L’environnement de staging est un environnement de test qui simule l’environnement de production réel. Il est utilisé pour effectuer des tests finaux avant de mettre une application en ligne.
- Utilisation : Il permet aux développeurs et aux équipes QA (assurance qualité) de tester des fonctionnalités, des mises à jour, des corrections de bugs, ou des nouvelles versions dans un environnement qui imite exactement la configuration de l’environnement live, mais sans affecter les utilisateurs finaux.
- Caractéristiques :
- Il contient des données de test ou une copie des données de production, mais ces données ne sont pas réelles.
- L’objectif est de s’assurer que tout fonctionne correctement avant de passer à la production.
- Les utilisateurs qui interagissent avec l’environnement de staging sont généralement des membres de l’équipe ou des testeurs internes.
- Environnement Live (Production) :
- But : L’environnement live, ou production, est l’endroit où l’application ou le site est réellement accessible par les utilisateurs finaux.
- Utilisation : C’est l’environnement où les utilisateurs interagissent avec l’application ou le site en temps réel. Il doit être stable, sécurisé et fiable, car toute modification ou panne peut affecter l’expérience utilisateur.
- Caractéristiques :
- Il contient des données réelles (utilisateurs, transactions, etc.).
- Toute modification apportée à cet environnement a un impact direct sur les utilisateurs finaux.
- Les mises à jour dans l’environnement live nécessitent des tests rigoureux et une gestion minutieuse pour éviter les erreurs et les interruptions de service.
Résumé :
- Staging = Environnement de test, simule la production, permet de tester des modifications avant de les appliquer en live.
- Live (Production) = Environnement réel utilisé par les utilisateurs finaux, toute modification a un impact immédiat.
En résumé, l’environnement de staging est une version de pré-production où les tests sont effectués pour vérifier qu’une nouvelle version de l’application fonctionnera correctement dans un environnement de production, avant d’être mise à la disposition des utilisateurs finaux.
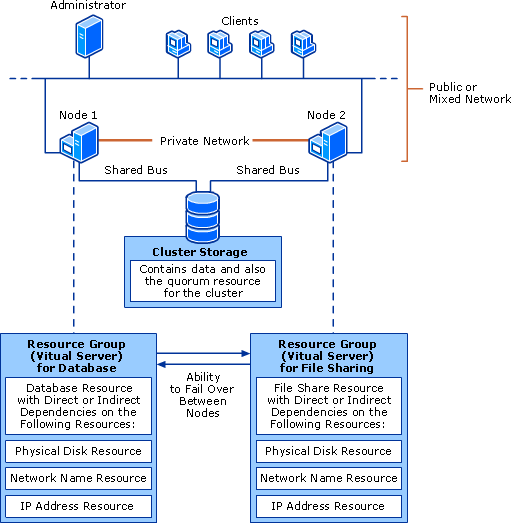
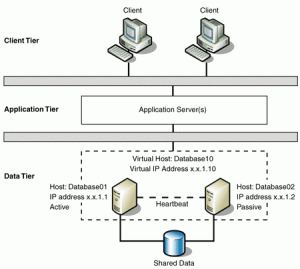 crease the availability of applications and services. The clustered servers (called nodes) are connected by physical cables and by software. If one of the cluster nodes fails, another node begins to provide service (a process known as failover). Users experience a minimum of disruptions in service. By using a failover cluster, you can ensure that users have nearly constant access to important server-based resources.
crease the availability of applications and services. The clustered servers (called nodes) are connected by physical cables and by software. If one of the cluster nodes fails, another node begins to provide service (a process known as failover). Users experience a minimum of disruptions in service. By using a failover cluster, you can ensure that users have nearly constant access to important server-based resources.